
Agent Oriented Programming

I run an AI-powered tutoring company called Orin. We provide a service to families, rather than being a tool for use. Here are some of our learnings so far about building AI-powered services.
Who’s This For?
This post is only applicable if you’re building a services business, not a tooling business. If you’re building a tool, then this is probably just bad advice.
How do I know if you’re building a tool or a service? It depends.
A general rule of thumb is “does my product make my customers more productive when they use it, or am I doing the work for them directly?” If you’re doing work for them—congrats! You’re a services business.
If not, you’re a tool (no offense).
The Anatomy of a Service
The line between a tool and service isn’t actually so clear. How much of the work does the tool need to do for me to become a service?
Is Cursor a tool? It sure does write a lot of my code. Isn’t that doing the work for me? How about my plumber?
Here are some good tests:
Does a user have to be knowledgable about the subject to be able to be a customer?
Most people using Cursor are engineers. Most people calling plumbers are not plumbers.
How hands-on are my users with the problem I’m solving?
Cursor users are pretty hands-on in the IDE. Lovable users seem to be pretty hands off. Plumbing (for me at least) is very hands-off.
Does the scope of work done in/with my product line up with the scope of work of a pre-existing job title?
This is usually a pretty good sign you’re a service. For example, I want to be able a text my plumber, and I want my coding agents to live in Slack and GitHub.
When building a services business, it turns out that the user not being involved is kind of the whole point. When I call a plumber, I’m paying to be able to go sit in another room and get work done while they fix the issue in my pipes. I don’t know how to fix it, and I don’t really want to do it. I’m happy to pay someone for that.
In fact, almost all services include steps where the buyer is not directly involved. This is critical to realize when building AI-powered services businesses.
Doing the core service (plumbing the pipes) is only one part of the product that we buy. A “good plumber” isn’t just good at plumbing—they’re communicative, organized, and well mannered.
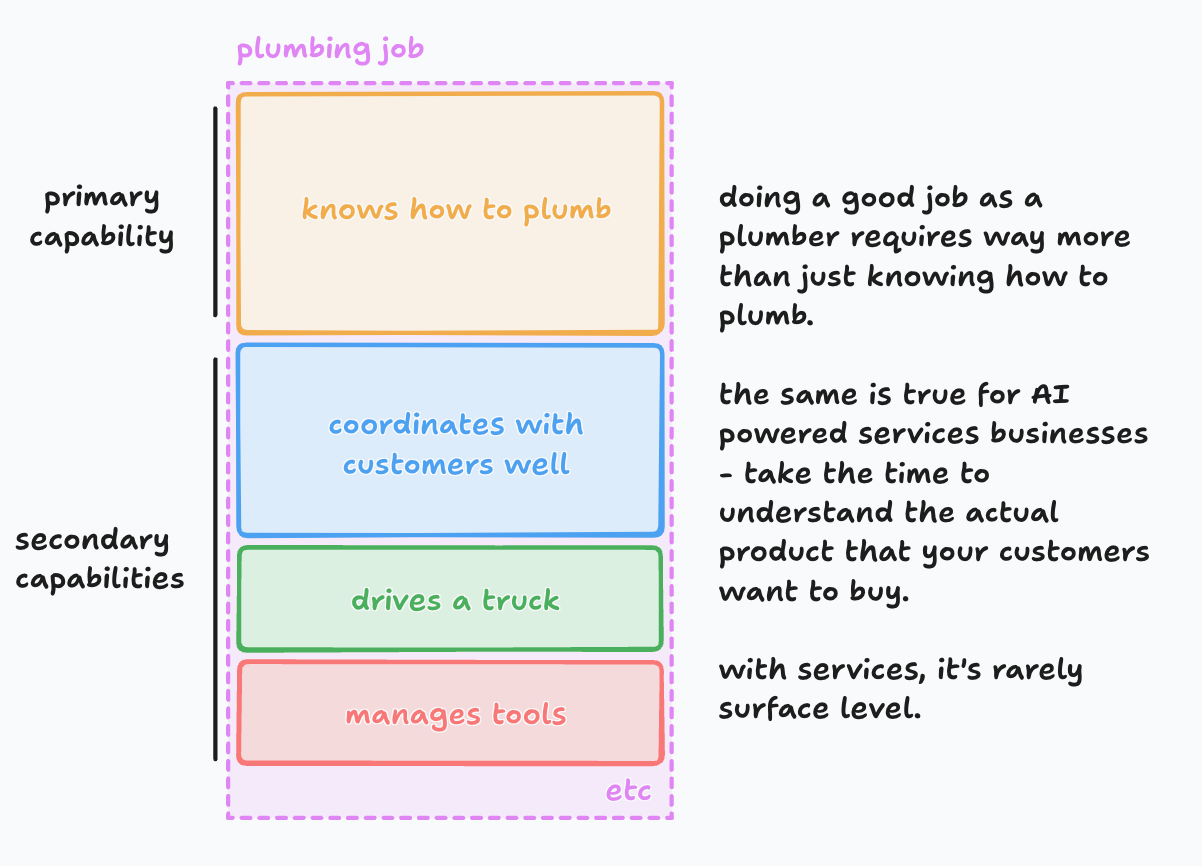
We can split these into “primary” and “secondary” capabilities, as shown above.
Capability is All You Need
AI agents struggle with services businesses. We build them to do one workflow (ie plumbing) but often forget about the rest of the job. This is what makes AI-powered services still not feel “human” enough.
But what makes a service feel “human”?
It’s the secondary capabilities.
It turns out that “how high-rez can we get our AI avatar” or “how natural does the voice sound” aren’t that important. Think about it—if we were on Zoom meeting, I could put my voice through a voice-changer and turn off my camera, yet I bet I would still feel human. As long as I’m fulfilling my job in that meeting (which often include secondary capabilities), I’ll feel real.
Our humanness lies mostly within our capabilities, not in our looks, conversational style, or anything else.
To stretch this example further, I could hire a real plumber, put them in a motion capture suit and a VR headset, have them control a humanoid robot remotely, and that would still feel very human. Even though you can literally see it’s a robot driving up your driveway and plunging your toilet.
With a human plumber involved, the secondary capabilities are implied:
If you need to reschedule, just text them and they can adapt.
Need to pay in cash? Probably not an issue.
If they’re stuck in traffic, they know how to communicate with you to keep you in the loop.
There are hundreds more of these implicit secondary capabilities that we assume humans have, which is why when we see a robot capable of them, we think: “human!”
So as you build your AI-powered services company, remember that the product you provide is not just plumbing toilets. It’s also the hundreds of edge cases around plumbing toilets, dealing with humans, and running into traffic.
For many jobs, the nominal value from the secondary capabilities eclipses the nominal value from the primary one.
Orient Around the Agent
Great, so how do we build secondary capabilities into our AI agents? We quickly run into a problem:
Many secondary capabilities require proactivity or do not directly involve the customer.
We’re very used to building software architectures, schemas, and teams around the customer. If the customer doesn’t trigger something, it doesn’t happen. I talk more about this in my post about building proactive agents.

But now, we want to build architecture around the agent instead of the customer. The customer is important, but not required for existence.
Example: If you’re building an agent that provides a service, you should not build memory around the customer. Many memory providers will actually enforce that you build around the customer by providing an API like:
client.add(messages, user_id="alex", metadata={"food": "vegan"})When building services, this is completely wrong. Instead, memory should be oriented around the agent itself providing the service. Memory should look like this:
client.add(messages, agent_id="abc123", metadata={"food": "vegan"})If you orient memory around the customer, then your agent cannot exist outside of the customer. Which, as we saw earlier, is not a good idea when building services.
Also, memory is currently too fragile to handle long-running services workloads and remember the specifics. Instead, offload specific memories into stateful tools, like an SMS inbox, with tool states siloed per agent.
You agent isn’t going to remember exactly what was sent to and from their phone, or when. Don’t expect it to. Use the limited memory capacity available for more important things that aren’t easily stored in a database.
We call these “stateful tools”. Good examples include an SMS inbox, email inbox, phone/voicemail app, calendars, todo lists, you name it. If you give your agent the same tools you’d give a human, then the usage patterns of that tool will be in-sample for the models.
Orienting around the agent usually means you’ll have to shard your memory and tool states for each customer unit, like this.
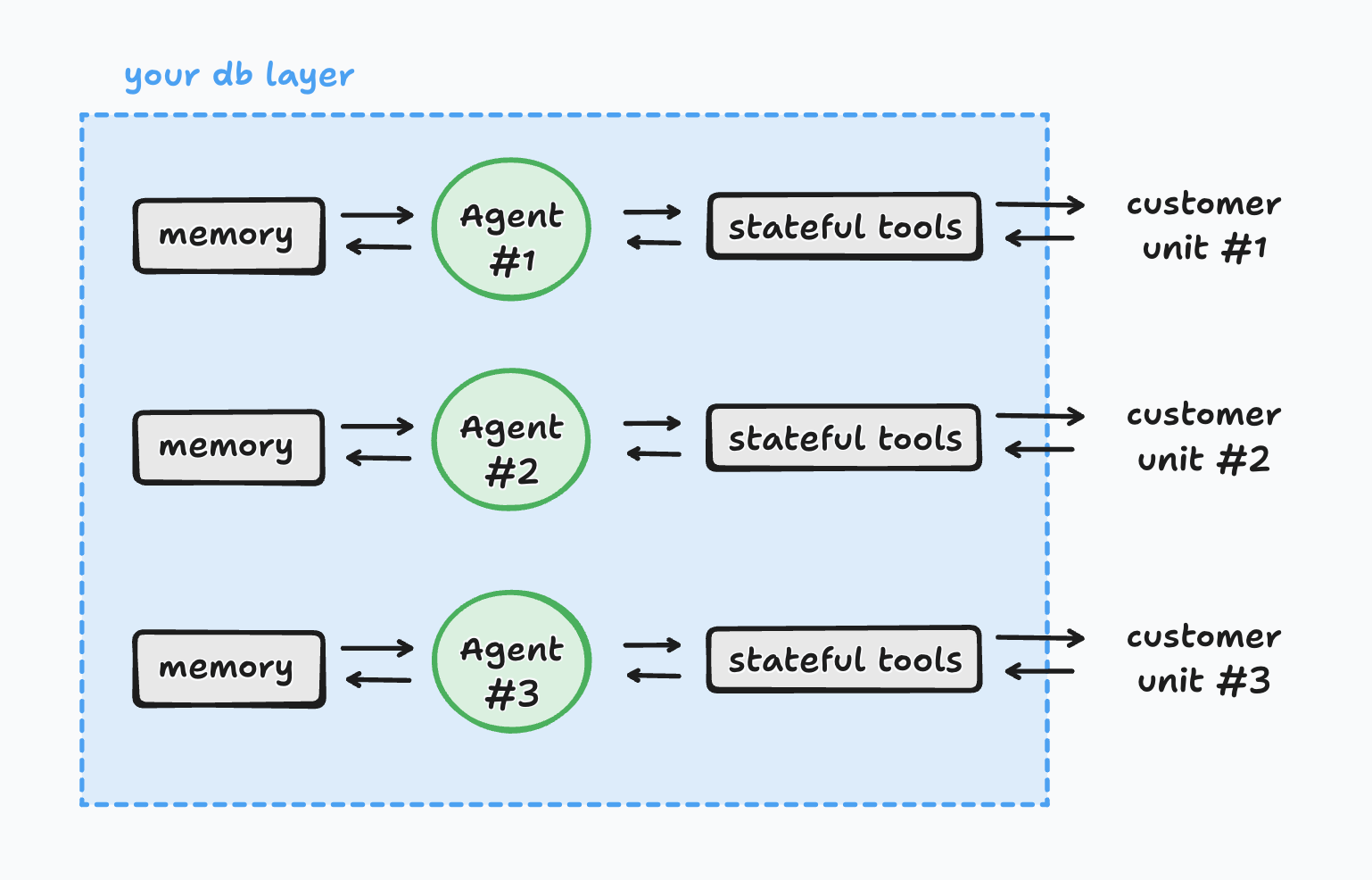
This is markedly different than the “spoke and wheel” model where you have one agent interacting with every customer.
If you define your customer unit properly (for us, customer unit = family), you’ll find that your architecture is much cleaner. You’ll naturally have siloed data, won’t risk leaking, and your context engineering will improve.
Conclusion
In short, I’d love to see more companies that focus on detaching their agent from their user. If you’re working on something like this, let me know! I’m bryan@learnwithorin.com.